UE5, 성능 손실 없이 더 많은 디테일을.
그리고 완전한 동적 라이팅을 향해.
UE4 후기에서 DX11(SM5)은 Compute Shader로 고정된 파이프라인의 틀을 느슨하게 만들었습니다. 반면 Tessellation은 더 많은 기하 디테일을 가능하게 했지만 성능, 크랙, 편차라는 숙제를 남겼습니다.
UE5는 DX12 시대의 조건에서 "성능 손실 없이 더 많은 디테일을, 그리고 완전한 동적 라이팅을" 이라는 도전을 하게 됩니다. 언제나 핵심은 구조 변화입니다. DX12는 GPU 작업을 드라이버가 자동 최적화해주던 시대에서 엔진이 명시적으로 자원을 배치하고 스케줄링하는 시대로 전환시켰습니다. 그렇게 Nanite와 Lumen은 이 전환을 전제로 설계되었습니다. 그 결과, 렌더링 파이프라인의 고정된 경계가 이전보다 훨씬 약해질 수 있었습니다.
UE4에서 남은 숙제: 디테일과 라이팅
UE4 후기의 DX11(SM5)은 Compute Shader를 통해 고정 파이프라인 외 연산 모델을 제공했고, Tessellation은 기하 디테일을 실시간으로 늘릴 수 있게 했습니다. 하지만 이 두 축은 어디까지나 가능성이었지 기본값은 아니었습니다. Tessellation은 성능 비용이 컸고, 크랙과 균열 문제와 하드웨어 편차도 존재했습니다. 또한 동적 라이팅은 여전히 제작 파이프라인에서 타협이 요구되는 영역이었습니다.
UE5는 이 숙제를 DX12 시대의 운영방식 위에서 다시 설계하였습니다.
많은 최적화가 드라이버 레이어에서 흡수되었던 DX11과는 달리 DX12에서는 자원 상태 전이(배리어), 파이프라인 상태(PSO), 리소스 바인딩 같은 비용을 엔진이 더 직접 관리하는 방향으로 움직였습니다. 이 변화는 기능 하나의 추가라기보다는 렌더러 설계가 CPU와 GPU의 협업(Scheduling, Batch, Caching) 중심으로 이동했다는 의미가 큽니다.
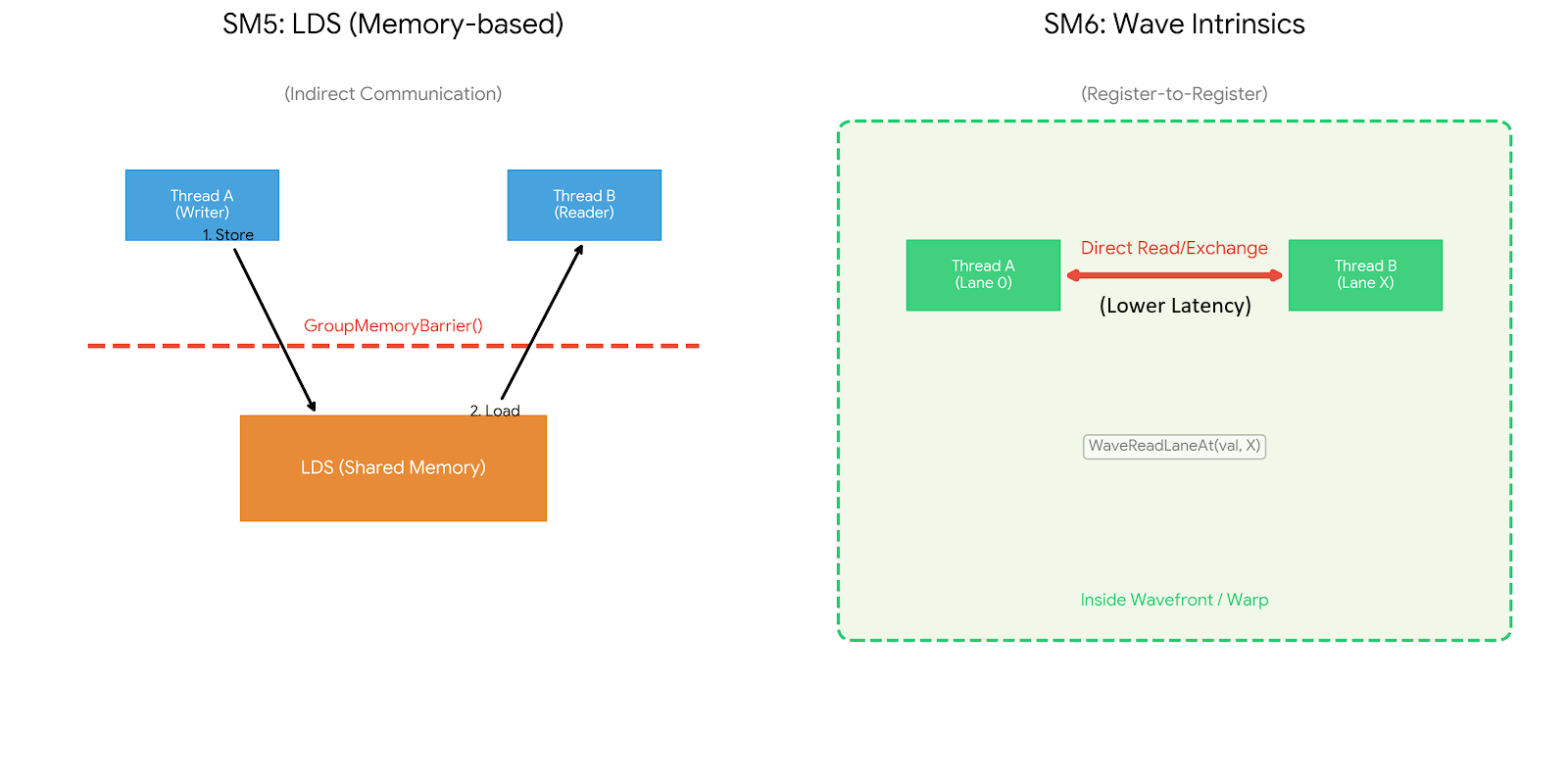
여기에 SM6의 Wave Intrinsics는 같은 웨이브(실행 그룹) 안의 lane들이 데이터를 교환 / 집계하는 연산을 가능하게 해 컬링이나 희소 데이터 패킹 같은 알고리즘에서 유리한 도구가 되었습니다. UE5의 바로 이런 Compute 중심, 데이터 지향 설계가 전제된 시대에 맞춰 Nanite와 Lumen가 탄생하게 되었습니다.
Nanite: 기하 디테일 문제를 바꾸다.

에픽게임즈는 Nanite를 가상화된 기하(Virtualized Geometry) 시스템으로 정의했습니다. 내부 메시 포맷과 렌더링 기술을 사용해 픽셀 스케일 디테일과 높은 오브젝트 수를 목표로 하며 화면에 보이는 디테일만 처리하도록 설계되었습니다. 또한 포맷은 고압축일뿐더러 세밀한 단위의 스트리밍과 자동 LOD까지 지원합니다.
이러한 내용이 중요한 이유는 UE4의 Tessellation이 표면을 더 쪼개는 증분적 디테일이었다면 Nanite는 디테일을 가진 원본을 받아들이되 런타임에서 가시성과 스트리밍으로 비용을 제어한다는 운영적 디테일로 축이 이동했기 때문입니다. 즉, UE5는 디테일을 늘리는 기술을 셰이더 단계의 기교가 아니라 데이터 포맷과 스트리밍, 그리고 컬링 파이프라인 전체의 문제로 끌어올리게 됩니다.
Nanite가 해결하려는 문제는 삼각형을 더 그리는 법이 아닙니다. 삼각형이 너무 많아진 시대에 "그것을 어떻게 운영할 것인가?"라는 물음에 대한 해법입니다. 즉, 내부 포맷으로 잘게 쪼개진 기하 데이터를 필요한 순간에만 스트리밍하고, 화면에 기여하지 않는 단위를 대규모로 컬링하며, 그 결과를 GPU 중심으로 빠르게 누적하고 결정해야 합니다.
이런 구조에서는 리소스 상태 전이나 바인딩, 파이프라인 상태 같은 비용이 반복적으로 등장할 수 밖에 없고, 이를 엔진이 명시적으로 통제하지 못하면 운영 자체가 불가능해집니다. 그래서 Nanite는 DX11처럼 드라이버 최적화에 기대기보다는 DX12의 명시적 모델 위에서 스케줄링, 배치, 캐싱을 엔진이 직접 설계하는 방향을 전제로 하게 됩니다. 또한 SM6의 웨이브 단위 협업은 이런 대규모 컬링과 패킹 과정에서 같은 실행 그룹 내부의 데이터 집계를 더 효율적으로 만들 수 있는 기반이 됩니다.
이 지점에서 DX12(SM6)는 선택이 아니라 조건이 됩니다. 왜냐하면 Nanite는 얼마나 많은 삼각형을 그릴 수 있는지를 넘어, 보이는 클러스터만 남기고 나머지는 버리는 GPU 주도 파이프라인을 전제하기 때문입니다.
Lumen: Bake 대신 Realtime을 기본값으로

에픽 문서를 보게되면 Lumen은 디퓨즈 간접광을 해결하며, 표면에서 반사된 색이 주변에 번지는 컬러 블리딩과 메시가 간접광을 가려 생기는 간접 그림자까지 포함한다고 하였습니다. 또한 반사(Reflections)까지 포함해 "동적 GI + 동적 반사"를 하나의 시스템으로 다룬다는 것을 설명합니다.
Lumen의 핵심은 동적 GI와 동적 반사를 옵션으로 더하는 것이 아니라 장면 변화(시간, 조명, 오브젝트, 카메라)에 따라 라이팅을 지속적으로 갱신하는 것을 기본 전제로 둔다는 점입니다. 이때 엔진은 광원, 표면, 가시성 정보를 반복적으로 업데이트하고, 그 과정에서 생성되는 데이터를 안정적인 GPU 작업으로 스케줄링 해야 합니다.
DX11처럼 많은 비용이 드라이버 레이어에서 흡수되던 모델에서는 이런 지속 갱신이 커질수록 제어가 어렵고, 반대로 DX12에서는 엔진이 배리어와 PSO, 리소스 바인딩을 포함한 실행 흐름을 명시적으로 설계할 수 있기 때문에 시스템 차원에서 동적 라이팅을 기본값으로 유지하는 운영 방식을 만들 수 있었습니다.
즉, Lumen은 단지 새로운 조명 기법이 아니라 DX12 시대의 엔진이 운영하는 방식을 전제로 성립하는 시스템입니다.
그렇기에 UE5 신규 프로젝트에서는 기본적으로 활성화되지만 기존 레거시로 인해 UE4에서 UE5로 변환한 프로젝트에서는 자동으로 활성화되지 않습니다. 이는 기존 프로젝트의 라이팅 패스를 망가뜨리거나 변경하지 않기 위한 조치로 명시되어 있습니다. 즉, Lumen은 단순한 옵션이 아니라, 제작 파이프라인의 기준선을 바꾸는 기능으로 취급됩니다.
UE4에서 동적 광원 수를 늘리는 접근이 CS 기반 컬링 같은 최적화를 요구했다면, UE5는 그 연장선에서 "동적 라이팅 그 자체를 기본값으로 두려면 무엇이 필요한가?"를 끊임없이 고찰하여 시스템차원으로 풀어낸 결과로 Lumen을 선보이게 됩니다.
맺음말
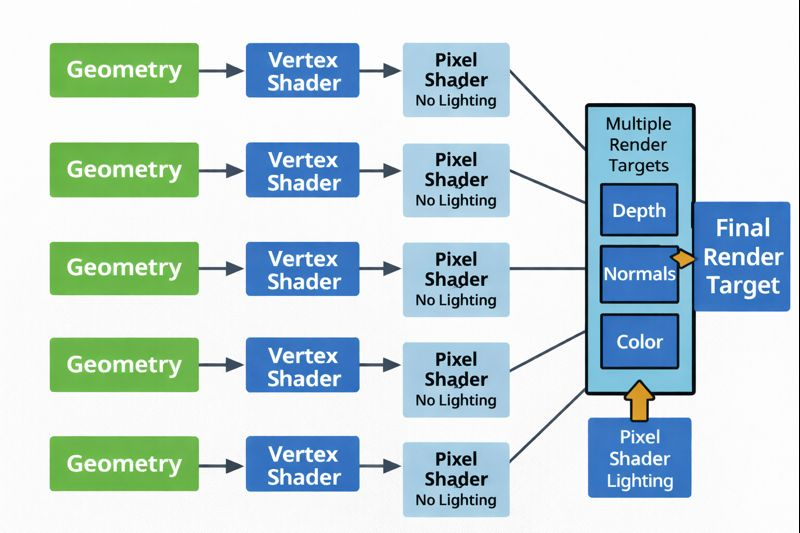
UE4(DX11 / SM5)는 고정 파이프라인을 깨기 시작했지만, 여전히 LOD는 사람이 설계하고, 라이팅은 베이크에 기대어 있었습니다. 하지만 UE5의 Nanite와 Lumen은 이 전제를 흔들었습니다.
- 기하는 LOD 설계에서 가상화와 가시성 기반 운영으로 이동한다.
- 라이팅은 베이크된 정답에서 실시간 해답을 기본 목표로 둔다.
따라서 UE5를 이해하는 핵심은 기능 소개가 아닙니다. DX12(SM6) 시대에 엔진이 GPU를 운영하는 방식이 바뀌어버렸고, Nanite와 Lumen은 그 운영 방식에 맞춰 렌더링을 데이터와 시스템 문제로 재정의 했다는 점에서 시사하는 바가 큽니다.
고정된 형식을 넘어 유연함을 추구하며 발전하는 GPU와 언리얼 엔진. 발전에는 끝이 없겠지만, 앞으로가 기대가 되는 GPU의 역사 시리즈를 마치겠습니다.
긴 시리즈를 마무리하며, 이 기술적 흐름에 공감해 주신 분들이 어떤 분들인지 궁금합니다.
아래 중 어디에 해당하시나요? 번호로 댓글만 남겨주시면 큰 힘이 됩니다.
- 취준생 / 학생: 엔진 내부 원리를 파헤쳐 압도적인 포트폴리오를 만들고 싶다.
- 현업 개발자: UE5 운영에서 최적화 vs 효율 사이에서 고민 중이다.
- 기술 결정권자: 엔진과 GPU 흐름을 읽고 팀의 기술 방향을 정해야 한다.
- 그 외 / 관심 독자: 일단 시리즈가 재미있어서 계속 보고 싶다.
특정 주제로 더 깊게 다이브하거나, 실무 적용 관점의 정리가 필요하다면 방명록(또는 이메일)로 편하게 노크해 주세요.
이메일 주소 : chessire@naver.com
이전글
UE4 후기 : 모던 렌더링 안정화와 (DX11-SM5)
DX11(SM5)은 UE4에게 ‘업데이트’가 아니라 구조 전환이었다.Compute Shader가 파이프라인의 고정관념을 깨고,Tessellation·PBR은 포토리얼리즘을 “실무”로 만들었다. 이전 글에서 다룬 DX11(SM5)의 등장
chessire.tistory.com
GPU의 역사 - 5 : DX12(SM6), Wave Intrinsics로 드러난 하드웨어 아키텍처
GPU의 역사 - 4 : DX11(SM5), Tessellation과 Compute ShaderGPU의 역사 - 3 : DX10/SM4와 Unified Shader 전환GPU의 역사 - 2 : SIMD에서 SIMT로, Branch DivergenceGPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반
chessire.tistory.com
'Game Programming > Unreal Engine' 카테고리의 다른 글
| UE4 후기 : 모던 렌더링 안정화와 (DX11-SM5) (0) | 2026.02.05 |
|---|---|
| UE4 전기: Unified Shader 이후 (0) | 2026.01.21 |
| UE3 - Forward Rendering을 넘어 Deferred Rendering으로 (0) | 2025.12.31 |
| Unreal Engine Physics Determinism: Lockstep (0) | 2025.12.10 |
| UE2의 Overlay Shader와 초기 Post Process Effect (0) | 2025.12.01 |