멀티스레드는 더 많은 코어가 아니라
더 적은 공유 write로 빨라집니다.
멀티스레드에서 제일 흔한 착각이 있습니다.
atomic이 느린 이유 = 락(lock) 때문
아니요. 많은 경우 atomic이 느린 이유는 락이 아니라,
캐시 라인 소유권(ownership) 경쟁 때문에 생기는 coherency 트래픽입니다.
3편에서 본 규칙을 그대로 가져오면 됩니다.
- read는 공유(S)로 버틸 수 있지만
- write는 독점(M/E)을 요구하고
- 누가 write를 시작하면 다른 코어의 라인은 invalidate 된다
atomic은 여기서 한 단계 더 빡셉니다.
atomic은 보통 RMW(Read-Modify-Write) 이기 때문입니다.

1) atomic이 비싼 진짜 이유: RMW는 라인 독점을 강제한다
atomic_fetch_add 같은 연산을 생각해봅시다.
- 값을 읽고
- 수정하고
- 다시 쓴다
이 3단계를 중간에 끼어들지 못하게 보장해야 합니다.
그래서 하드웨어는 대체로 다음을 요구합니다.
해당 캐시 라인을 내가 독점(M/E)해야만 RMW를 수행할 수 있다.
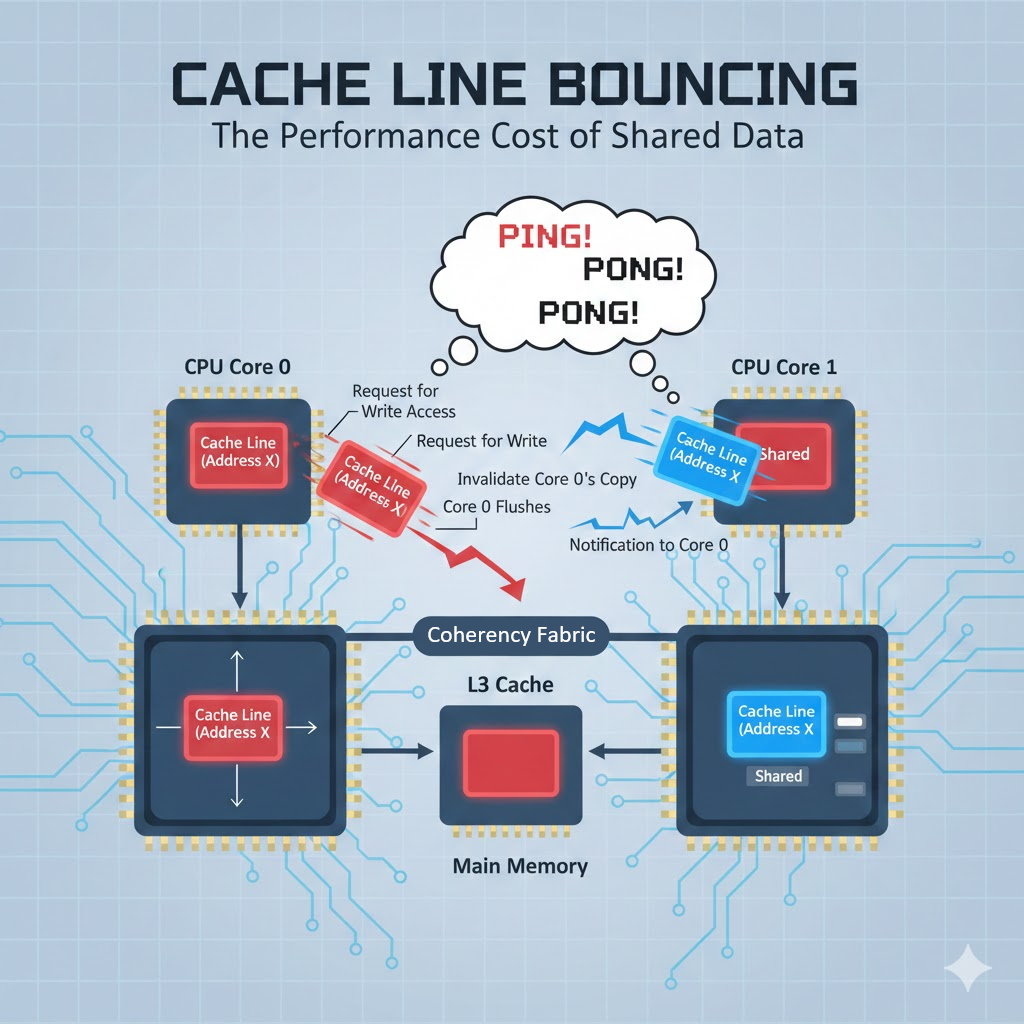
문제는 여러 코어가 같은 atomic을 동시에 건드릴 때 터집니다.
- Core0가 라인 독점 → Core1은 invalidate
- Core1이 라인 독점 → Core0는 invalidate
- 결과: 라인이 ping-pong (False Sharing과 구조가 동일)
여기서 중요한 결론:
atomic 경쟁(contended atomic)은 연산 비용이 아니라 라인 이동 비용으로 느려진다.
그래서 스레드를 늘리면 오히려 느려지는 현상이 나옵니다.
CPU가 일을 더 하는 게 아니라, 서로 밀어내느라 시간을 씁니다.
2) Uncontended atomic vs Contended atomic (진단 기준)
atomic이 항상 나쁜 건 아닙니다. 구분이 필요합니다.
Uncontended atomic (경쟁 없음)
- 한 코어만 해당 atomic을 자주 업데이트
- 또는 업데이트 빈도가 낮아서 충돌이 거의 없음
이 경우는 대체로 괜찮습니다.
Contended atomic (경쟁 있음)
- 여러 스레드가 같은 atomic(같은 캐시 라인)을 고빈도로 RMW
- 대표: 전역 카운터, 전역 큐 인덱스, 글로벌 통계, 글로벌 work counter
이 경우는 거의 확실히 병목입니다.
락이 없어도 느립니다. (락이 아니라 coherency 경쟁이니까)
3) 처방의 방향은 단 하나: 공유 write-hot을 없애라
4편의 실전 처방은 여기로 수렴합니다.
- 공유 write-hot을 스레드 로컬로 분해
- 필요한 순간에만 합친다(reduction)
- 합치는 지점도 가능하면 저빈도 / 배치(batch)로 만든다
즉, atomic을 잘 쓰는 법이 아니라
atomic을 ‘뜨거운 루프에서’ 치워버리는 법
이 핵심입니다.
4) 처방 1: per-thread counter + reduction (가장 강력하고 가장 흔함)
나쁜 예: 모든 스레드가 전역 atomic++
std::atomic<uint64_t> gCount = 0;
void Worker()
{
for (...)
{
gCount.fetch_add(1, std::memory_order_relaxed);
}
}이 코드는 연산이 아니라 라인 소유권 ping-pong으로 느려집니다.
좋은 예: 스레드 로컬 누적 + 마지막 합산(reduction)
std::atomic<uint64_t> gCount = 0;
void Worker()
{
uint64_t local = 0;
for (...)
{
local++;
}
gCount.fetch_add(local, std::memory_order_relaxed); // 빈도 1회
}핵심은 fetch_add 횟수를 줄이는 게 아닙니다.
라인 소유권 경쟁을 루프 밖으로 빼는 것입니다.
전역 atomic은 루프마다가 아니라 배치로 접근하라.
5) 처방 2: per-thread data layout (스레드별 write-hot을 구조적으로 분리)
reduction이 항상 가능한 건 아닙니다.
큐 인덱스, 작업 분배, 스레드 상태처럼 실시간으로 공유해야 하는 값이 존재합니다.
이때는 최소한 이렇게 해야 합니다.
서로 다른 스레드가 쓰는 데이터가 같은 캐시 라인에 들어가지 않게 한다.
즉, 2편에서 다룬 alignas(64)의 진짜 목적이 여기서 다시 등장합니다.
패턴: thread slot을 캐시 라인 단위로 고정
struct alignas(64) ThreadSlot
{
uint64_t counter; // padding은 컴파일러/플랫폼에 따라 달라질 수 있음
char pad[64 - sizeof(uint64_t)];
};
ThreadSlot slots[MAX_THREADS];
void Worker(int tid)
{
for (...)
{
slots[tid].counter++; // 각자 자기 라인만 건드림
}
}이 설계는 속도 최적화라기보다
coherency 트래픽 최악 케이스 제거(안정화)입니다.
6) 처방 3: 큐/링버퍼는 head/tail(메타데이터)을 분리하라
Lock-free 큐에서 흔한 병목은 알고리즘이 아니라 메타데이터 배치입니다.
- head와 tail이 같은 캐시 라인에 있으면
- producer/consumer가 서로 다른 변수를 업데이트해도
- 같은 라인을 두고 ping-pong이 납니다 (False Sharing)
원칙
- head와 tail을 다른 캐시 라인으로 분리
- size/flags 같은 write-hot 메타데이터도 분리
이건 구조가 복잡해지기 전에 적용할수록 효과가 큽니다.
7) atomic을 써야 한다면: 최소한 이 관점으로 사용해라
atomic을 완전히 없앨 수 없는 경우도 있습니다.
그럴 때의 원칙은 단순합니다.
(1) hot loop에서 atomic을 빼라
- 루프 안에서 1회를 루프 밖에서 1회로 바꿔라 (batch)
(2) 공유 write-hot을 줄여라
- write 빈도를 낮추거나, 스레드별로 나누고 합쳐라
(3) 같은 라인을 두 스레드가 건드리지 않게 배치하라
- per-thread slot
- alignas(64) 또는 명시적 padding
여기까지 하면 atomic이 락처럼 느려지는 대부분의 상황은 정리됩니다.
8) 체크리스트: 이 조건이면 atomic 병목을 의심해라
- 스레드를 늘렸는데 throughput이 거의 안 오르거나 떨어진다
- 전역 카운터/통계/큐 인덱스가 hot path에 있다
- 프로파일에서 모두가 같은 위치를 건드린다는 냄새가 난다
- 락은 없는데도 CPU가 바쁘고 일이 안 끝난다
이때는 먼저 묻는 게 맞습니다.
“나는 지금 연산을 하고 있나, 아니면 캐시 라인 소유권을 주고받고 있나?”
마무리: 멀티스레드 최적화의 본질
시리즈를 4편까지 오면 결론은 선명해집니다.
- 1편: CPU는 연산보다 물류(메모리/캐시)가 문제다
- 2편: 멀티코어는 shared cache line 때문에 무너진다 (False Sharing)
- 3편: Invalidate는 감이 아니라 MESI 규칙으로 발생한다
- 4편(오늘): atomic의 비용은 락이 아니라 라인 소유권 경쟁이다
그래서 실전 처방도 단순합니다.
- 공유 write-hot을 없애라
- 스레드별로 누적하고 마지막에 합쳐라(reduction)
- 어쩔 수 없이 공유하면 라인을 분리하라(alignas(64), layout)
이전글
'Notes > Computer Science' 카테고리의 다른 글
| 첫 번째 가상화 레이어 Virtual Memory - 가상화의 역사 1 (0) | 2026.04.13 |
|---|---|
| Invalidate를 줄이는 법: MESI로 이해하는 캐시 라인 소유권 경쟁 (0) | 2026.03.26 |
| 현대 CPU 최적화의 본질: 연산(ALU)이 아닌 메모리(LSU) (0) | 2026.03.12 |
| 당신의 멀티스레드가 느린 이유: False Sharing과 alignas(64)의 진실 (0) | 2026.03.05 |
| OSI 7계층과 TCP/IP 4계층 (0) | 2010.08.23 |