CPU는 연산보다
데이터를 가져오는 방식에
훨씬 민감하다.
CPU 최적화를 연산을 줄이는 일로만 보면, 체감 성능이 잘 안 나옵니다. 실전 병목은 대개 계산(ALU)이 아니라 메모리 접근(Load/Store)에서 터집니다. CPU는 load => execute => add 같은 일을 파이프라인으로 겹쳐서 처리할 수 있지만, 데이터가 제때 도착하지 않으면 실행 유닛은 그냥 놀게 됩니다.

1) 패러다임 전환: 연산이 아니라 물류(Load/Store)가 문제다
CPU 내부엔 역할 분리가 있습니다.
- LSU(Load/Store Unit): 메모리를 읽고/쓰는 담당
- ALU/FPU/SIMD: 실제 계산 담당
코드가 느릴 때 계산량이 많아서일 수도 있지만, 더 흔한 케이스는 이겁니다.
- 계산은 준비됐는데 로드가 늦어서 실행이 멈춘다.
- 실행 중에 다음 데이터를 추가로 로드하려다가 캐시 미스로 브레이크가 걸린다.
그래서 최적화의 시작점은 연산 줄이기가 아니라 캐시 히트율을 올리는 데이터 배치입니다.
2) 캐시의 작동 원리: CPU는 64B ‘박스’ 단위로 움직인다
캐시는 바이트 단위로 움직이지 않습니다. 보통 캐시 라인(Cache Line) 단위(대부분 64B)를 최소 단위로 가져오고 버립니다.
여기서 지역성이 나옵니다.
- 공간 지역성(Spatial): 다음에 접근할 메모리가 인접해 있다.
- 시간 지역성(Temporal): 방금 접근한 메모리를 곧 다시 쓴다.
즉, 우리가 코드를 예측 가능하게 만든다는 말의 실체는 대부분 이겁니다.
- 인접 데이터를 연속으로 쓰게 만들고(공간)
- 최근에 쓴 데이터를 다시 쓰게 만들면(시간)
- 캐시 히트율이 올라가고, 로드 지연이 줄어듭니다.
3) 예측 실패보다 무서운 설계 실수: 캐시 미스는 4C로 보자
교과서적 분류는 3C(Cold/Capacity/Conflict)지만, 멀티코어까지 다루려면 4C가 더 정합적입니다.
4C Cache Miss
- Cold (Compulsory) Miss
처음 접근이라 캐시에 없어서 발생. - Capacity Miss
캐시 용량 자체가 부족해서, 담아두지 못하고 밀려남. - Conflict Miss
캐시에 공간은 있는데 매핑/세트 충돌 때문에 교체가 과하게 발생.
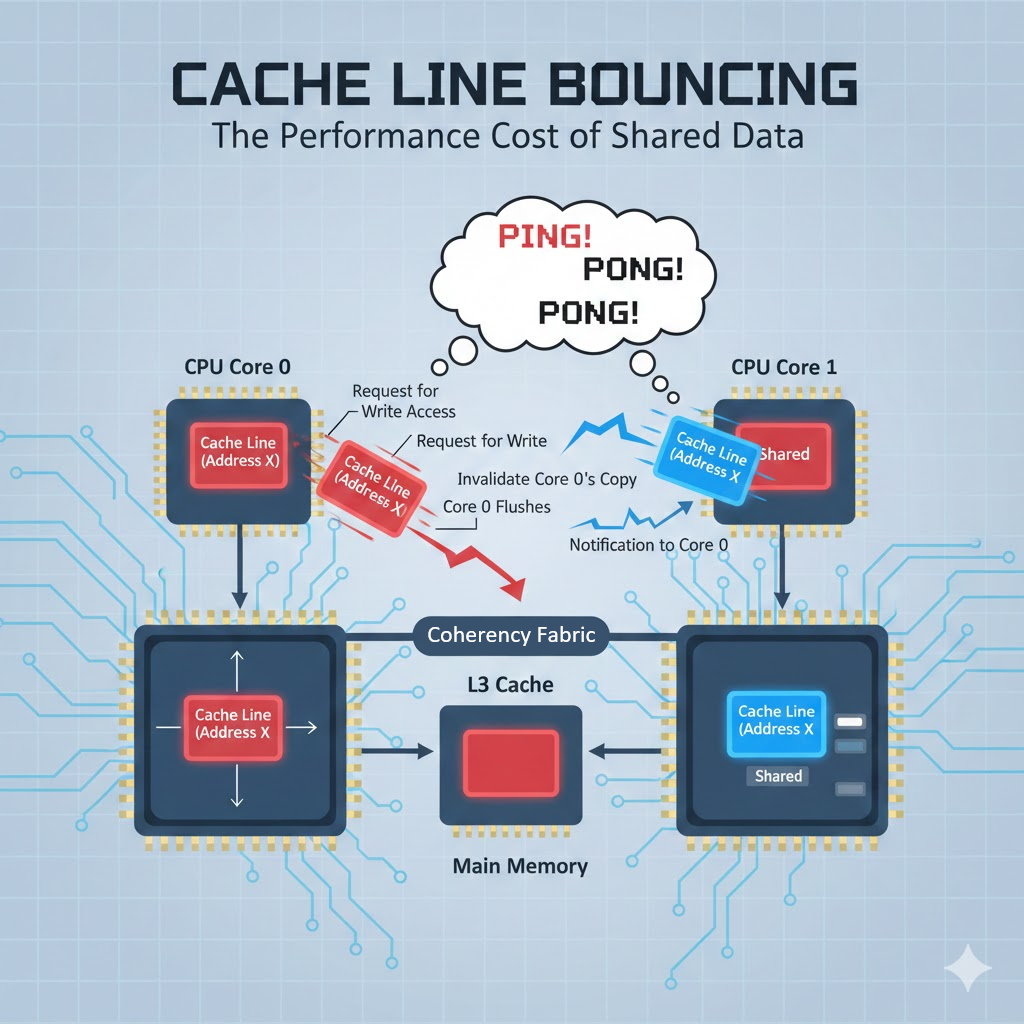
특히 stride 패턴이 캐시 인덱스와 맞물리면 계속 갈아엎는 현상이 나옵니다. - Coherency Miss (일관성 미스)
다른 코어가 내가 들고 있던 캐시 라인을 수정해서 Invalidate가 걸린 경우.
이게 나중에 말할 False Sharing의 바로 그 뿌리입니다.
여기서 중요한 건, 미스를 예측 실패 하나로 뭉개면 원인 진단이 틀어진다는 점입니다.
Capacity인지, Conflict인지, Coherency인지에 따라 처방이 완전히 달라집니다.
4) Stride 프리패처: CPU는 일정 보폭을 좋아한다
하드웨어 프리패처는 다음 줄을 무조건 읽어오기만 하지 않습니다. 규칙적인 보폭(Stride)을 학습합니다.
예를 들어:
- [0] -> [4] -> [8] -> [12] 처럼 일정하면
→ 4칸씩 뛴다는 점을 학습하고 미리 끌어옵니다.
반대로,
- stride가 너무 크거나(Large Stride)
- 접근 주소가 불규칙하게 튀면(Random)
→ 프리패처가 포기하거나 정확도가 떨어집니다.
이 지점이 CPU가 좋아하는 데이터 배치의 현실적인 기준입니다.
연속 배열 + 규칙적 루프는 프리패처, 캐시, SIMD까지 한 번에 정렬됩니다.
5) 구조체 설계의 정석: 무조건 alignas가 아니라 데이터 구겨넣기(Packing)가 먼저다
정렬(Alignment)은 분명 도움이 됩니다. 특히 캐시 라인을 걸치지 않게 만들거나, 멀티스레드에서 라인 공유를 피하는 데도 쓰입니다. 하지만 무작정 alignas(64)부터 박으면 이런 문제가 생깁니다.
- 구조체가 작아도 64B 패딩이 붙어 캐시 오염(cache pollution)이 생김
- 결과적으로 실제 유효 데이터 대비 로드량이 늘어서 히트율이 떨어질 수 있음
그래서 우선순위는 보통 이 순서가 맞습니다.
- 필드 재배치 / 타입 정리로 패딩을 줄인다.
- 남는 공간은 자주 쓰는 필드로 메꿔서 64B를 꽉 채운다. (패킹)
- 그래도 필요할 때만 alignas(64) 같은 강제 정렬을 쓴다.
그리고 여기서 다음 글 떡밥이 자연스럽게 이어집니다.
- 구조체를 64B 정렬하는 이유는 속도만이 아니라
멀티코어에서 False Sharing(거짓 공유)를 피하기 위한 목적도 큽니다.
(서로 다른 스레드가 같은 캐시 라인을 건드리면 Coherency Miss가 폭발합니다.)

6) AoS vs SoA: 데이터의 본질이 아닌 접근 패턴으로 결정한다
여기서 정답을 단정하면 항상 사고가 납니다. 결론은 하나입니다.
AoS/SoA는 취향이 아니라,
루프의 형태로 결정한다.
AoS (Array of Structures)
- 개체 하나를 잡고 여러 필드를 같이 만지는 패턴에 유리
- 단점: 특정 필드만 훑을 때 불필요한 데이터까지 같이 로드될 수 있음
struct Agent { float pos, vel, health; };
Agent agents[100];SoA (Structure of Arrays)
- 같은 필드를 대량으로 훑는 패턴(예: pos만 10만 개 업데이트)에 유리
- 장점: 캐시/프리패처/SIMD와 궁합이 좋은 경우가 많음
- 단점: 개체 단위로 여러 필드를 동시에 만지면 오히려 산개 접근이 될 수 있음
struct AgentGroup { float pos[100], vel[100], health[100]; };※ 참고로 Epic Games의 Unreal Engine 쪽에서 ECS 계열(예: Mass 같은 접근)을 떠올릴 수 있는데, 엔진 기능 자체보다 중요한 건 “내 루프가 무엇을 연속으로 훑는가”입니다. 기능 이름보다 접근 패턴이 먼저입니다.
7) 현대 하드웨어의 복잡성: L3 포함 정책은 유연해지는 추세
마지막으로, 멀티코어 시대에 L3 정책 이야기를 안 하면 반쪽입니다.
- L1/L2: 코어 전용, 빠르고 작음
- L3: 여러 코어가 공유, 상대적으로 크고 느림
여기서 Inclusive / Non-Inclusive 얘기가 나오는데, 포스팅에서 중요한 태도는 이겁니다.
- 제조사별 경향성은 참고 가치가 있지만
- 최근에는 코어 수 증가와 L3 효율 문제 때문에
두 진영 모두 정책을 더 유연하게 가져가는 추세라는 점을 같이 적는 게 신뢰도가 높습니다.
즉, 브랜드로 단정하기보단 마이크로아키텍처/제품군 기준으로 확인하는 게 맞습니다.
(특히 서버/워크스테이션 라인업은 정책이 다르게 나타나는 경우가 많습니다.)
여기서 Intel / AMD 비교를 할 때도 단정이 아니라 확인이 핵심입니다.
이 글의 결론, “캐시를 설계하라”
CPU 최적화는 결국 이 두 문장으로 요약됩니다.
- 연산보다 로드가 먼저 병목이다.
- 캐시는 라인 단위로 움직이고, 미스는 4C로 구분해야 한다.
다음 글에서 이어설명할 주제는 아래와 같습니다.
- Coherency Miss와 False Sharing
- 왜 alignas(64)가 속도가 아니라 멀티코어 안정성의 문제인지
- 그리고 멀티스레드에서 캐시 라인을 어떻게 분리/배치할지
이전글
당신의 멀티스레드가 느린 이유: False Sharing과 alignas(64)의 진실
Coherency Miss(일관성 미스)로 보는캐시 라인 전쟁과 해결 전략,alignas(64)는 속도가 아니라멀티코어 안정성이다.싱글 스레드 최적화는 보통 캐시 히트율로 설명이 끝납니다.하지만 멀티스레드에 들
chessire.tistory.com
'Notes > Computer Science' 카테고리의 다른 글
| Atomic: 락이 아니라 캐시 라인 소유권 경쟁이다. (0) | 2026.03.30 |
|---|---|
| Invalidate를 줄이는 법: MESI로 이해하는 캐시 라인 소유권 경쟁 (0) | 2026.03.26 |
| 당신의 멀티스레드가 느린 이유: False Sharing과 alignas(64)의 진실 (0) | 2026.03.05 |
| OSI 7계층과 TCP/IP 4계층 (0) | 2010.08.23 |
| 네트워크의 주소체계와 데이터 정렬 (0) | 2010.08.17 |