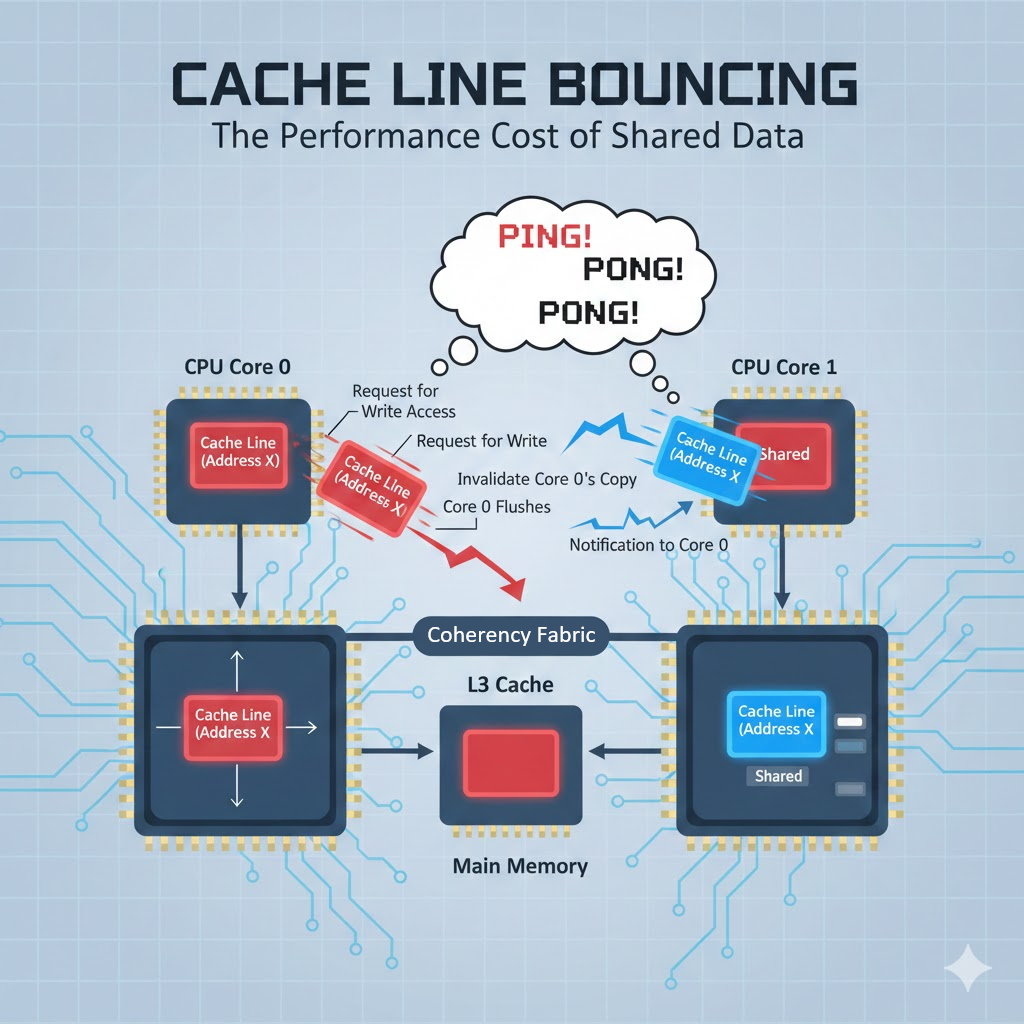
다른 코어가 같은 캐시 라인을 가진 상태에서,
누군가 그 라인을 write(특히 RMW)로 독점하려는 순간.
Invalidate가 터진다.
우리는 False Sharing을 캐시 라인 ping-pong으로 봤습니다.
그런데 여기서 한 단계 더 정확해져야 해요.
Invalidate는 캐시 미스가 아니라, 쓰기 권한(소유권) 경쟁 때문에 발생한다.
즉, 멀티코어에서 느려지는 이유는 데이터가 멀리 있어서가 아니라
누가 그 캐시 라인을 ‘쓰기 가능한 최신 상태’로 갖고 있느냐를 맞추느라 트래픽이 터지기 때문입니다.
이걸 설명하는 최소 모델이 MESI입니다.
0) MESI를 한 문장으로 정의
캐시 라인(보통 64B)마다 CPU는 “이 라인이 지금 어떤 상태인가”를 관리합니다.
- M (Modified): 내가 수정했고(Dirty), 최신. 다른 코어는 못 가짐
- E (Exclusive): 나만 가지고 있고 최신. 아직 수정은 안 했음
- S (Shared): 여러 코어가 읽기용으로 공유 중
- I (Invalid): 무효(없다고 봐도 됨)
여기서 핵심은 딱 하나:
쓰기(write)는 ‘독점(Exclusive)’ 상태를 요구한다.
그래서 누가 쓰려고 하면, 다른 코어의 같은 라인은 Invalidate(I) 된다.
1) 읽기만 하면 보통 큰 싸움이 없다 (Read / Read)
두 코어가 같은 주소 X를 읽기만 한다고 하자.
- Core0: X를 읽음 → E 또는 S (상황에 따라)
- Core1: X를 읽음 → 둘 다 S로 수렴
여기서는 보통 Invalidate 폭발이 없습니다.
왜냐하면 읽기는 최신성만 맞으면 되고, 독점 소유권이 필요 없기 때문입니다.
결론: Read-mostly 공유는 비교적 안전하다.

2) 누군가 쓰기를 하는 순간부터 Invalidate가 시작된다 (Read / Write)
이제 Core1이 X를 write 한다고 하자. (X++ 같은 수정)
이미 Core0이 X를 S 상태로 갖고 있었다면?
- Core1은 쓰기 위해 X를 독점 상태(M / E)로 만들어야 함
- 그래서 Core0의 X는 I(Invalid) 로 바뀜
즉, 규칙은 간단합니다.
다른 코어가 같은 캐시 라인을 가지고 있는데, 누군가 write를 하려는 순간 → Invalidate 발생
이때 Core0는 내 캐시에 분명히 있었는데(I로 바뀌어서) 다시 가져와야 하고,
이게 Coherency Miss로 관측됩니다.
3) 최악은 Write / Write: 소유권이 공처럼 튕긴다 (Ping-Pong)
False Sharing이 터지는 대표 상황이 이거죠.
- Core0: 라인 X의 어떤 필드(변수 A)를 계속 write
- Core1: 같은 라인 X의 다른 필드(변수 B)를 계속 write
둘은 논리적으로 다른 변수지만, 캐시 라인이 같으면 같은 전쟁입니다.
흐름은 이렇게 됩니다.
- Core0 write → X를 M로 만든다 (Core1 쪽 X는 I)
- Core1 write → X를 M로 만들려 한다 → Core0 쪽 X는 I
- Core0 write → 다시 독점 필요 → Core1 쪽 I
… 무한 반복
여기서 중요한 포인트:
- 값 자체의 충돌이 없어도
- 캐시 라인 소유권 때문에
- Invalidate가 매번 발생한다.
결론: False Sharing은 shared data가 아니라 shared cache line 문제다.
4) 왜 RMW(atomic)이 특히 비싼가: 독점 + 순서를 강제한다
다음 편에서 atomic을 깊게 다루겠지만, 원리만 여기서 박아두면 이렇습니다.
atomic_fetch_add 같은 연산은 단순 write가 아니라 Read-Modify-Write입니다.
- 값을 읽고
- 수정하고
- 다시 쓰는 작업
이건 의미상 중간에 다른 코어가 끼면 안 되기 때문에,
하드웨어는 보통 해당 라인을 더 강하게 독점하려고 합니다.
즉, 경쟁 상황에서 atomic은 이렇게 동작해요.
- 여러 코어가 동일 라인에 대해 RMW를 시도
- 각 코어가 “내가 지금 독점해서 처리해야 함”을 강제
- 결과적으로 invalidate + 소유권 이동이 더 자주, 더 비싸게 발생
그래서 atomic 비용을 락이니까 느리다고만 보면 진단이 반쯤 틀립니다.
atomic의 핵심 비용은 락이 아니라, 캐시 라인 소유권 경쟁(= coherency 트래픽)이다.
이게 4편의 주제가 됩니다.
5) 이 규칙을 코딩 관점으로 번역하면
MESI를 외우는 목적은 상태도를 잘 그리자는 게 아닙니다.
코드를 이렇게 분류하기 위해서예요.
안전한 패턴(대체로)
- read-mostly 공유 (초기화 후 읽기 전용)
- 스레드마다 자기 데이터에 write (서로 다른 라인)
위험한 패턴(거의 확실히 터짐)
- 여러 스레드가 같은 라인에 write
- 서로 다른 변수라도 같은 캐시 라인이면 동일하게 위험
- 경쟁 상황의 atomic RMW (특히 hot counter)
여기서 2편에서 말한 alignas(64)가 다시 의미를 갖습니다.
- alignas(64)는 단순히 빠르게 하는 것이 아니라
- write-hot 데이터가 같은 캐시 라인을 공유하지 않게 하는 장치
- 즉 Invalidate 규칙을 회피하는 설계입니다.
마무리
여기까지 정리하면, 멀티스레드에서 성능이 무너지는 이유는 CPU가 느려서가 아닙니다.
대부분은 캐시 라인(64B) 소유권을 두고 벌어지는 규칙적인 싸움입니다.
- 읽기(Read)는 공유(S)로 공존할 수 있지만
- 쓰기(Write)는 독점(M/E)을 요구하고
- 그 순간 다른 코어의 동일 라인은 Invalidate(I) 됩니다.
- 이 Invalidate가 반복되면, 우리가 2편에서 본 ping-pong(= False Sharing)이 됩니다.
즉, False Sharing은 공유 데이터 문제가 아니라
공유된 캐시 라인(shared cache line) 문제입니다.
이제 다음 질문이 자연스럽게 남습니다.
“그럼 atomic은 왜 이렇게 비싼가? 락이 없는데도 왜 느려지나?”
답은 이미 보입니다. atomic은 단순 write가 아니라 RMW(Read-Modify-Write)이고,
RMW는 캐시 라인의 독점 소유권과 순서를 더 강하게 요구합니다.
그래서 병목은 락이 아니라 coherency 트래픽으로 나타납니다.
다음 편에서는 이 지점을 정확히 파고들어,
atomic의 비용을 락이 아니라 캐시 라인 소유권 경쟁으로 재정의하고
실전에서 바로 쓰는 per-thread data layout / reduction 패턴으로
멀티스레드 성능을 안정화하는 방법까지 마무리하겠습니다.
'Notes > Computer Science' 카테고리의 다른 글
| 첫 번째 가상화 레이어 Virtual Memory - 가상화의 역사 1 (0) | 2026.04.13 |
|---|---|
| Atomic: 락이 아니라 캐시 라인 소유권 경쟁이다. (0) | 2026.03.30 |
| 현대 CPU 최적화의 본질: 연산(ALU)이 아닌 메모리(LSU) (0) | 2026.03.12 |
| 당신의 멀티스레드가 느린 이유: False Sharing과 alignas(64)의 진실 (0) | 2026.03.05 |
| OSI 7계층과 TCP/IP 4계층 (0) | 2010.08.23 |