
Unified Shader는 단계 통합이 아니다.
VS / GS / PS가 같은 공용 코어 풀을 공유하는 구조 전환이다.
지난 시간, SIMT모델과 그것의 가장 좋은 사례인 UE3에 대해서 알아보았습니다. 이번 시간에는 DX9(SM3) 이후 DX10(SM4)이 등장하면서 Unified Shader가 왜, 어떻게 전환됐는지 알아보도록 하겠습니다.
Unified Shader의 등장(DX10, SM4)
VS / PS 같은 단계별로 유닛을 분리하여 Programmable Shader를 실행해 연산을 처리하던 DX9에도 문제점은 있었습니다. 바로 각 단계에서 워크로드가 한쪽 단계로 쏠리면 다른 단계의 유닛이 유휴(idle) 상태가 되는 로드 불균형이 발생하는 점이었습니다. 기존 DX9시절 GPU는 기본적으로 Vertex 쪽과 Pixel 쪽 연산 코어는 분리 설계가 더 저렴하고 빠르고 구현이 단순했기 때문에 분리되어 있었습니다. FFP의 유산으로 단계별 파이프를 만들기가 더 쉬웠죠.
이 부분을 더 자세히 들여다보면 SM2 / SM3 시절엔 실제로 VS / PS가 지원하는 기능이 미묘하게 달랐습니다. Pixel 쪽은 화면상의 2x2 quad 기반 파생값(ddx/ddy), 보간, 텍스처 접근 패턴 등 "래스터 기반 규칙"이 강했습니다. 하지만 Vertex 쪽은 그런 제약이 상대적으로 적고, 대신 기하 데이터 처리에 최적화 돼 있었습니다. 즉, "둘 다 셰이더니까 코어를 공유하면 되지 않나?"가 오늘 관점에서는 쉬워보여도 당시에는 실행 조건이 달라서 코어를 공용화하려면 추가 하드웨어, 규칙 정리가 필요했습니다.
(참고로 SM3의 VS에서도 텍스처 룩업 자체는 가능했지만, 픽셀 단계의 2x2 quad 기반 파생값(ddx/ddy) 같은 래스터 규칙은 본질적으로 픽셀 단계에 묶여 있었습니다.)
게다가 부하가 한쪽으로 쏠릴 때 발생하는 손해가 그때는 덜 치명적이기도 했습니다. DX9 시절의 게임은 평균 해상도, 셰이딩 복잡도, 포스트프로세스가 지금보다 낮았고, 파이프라인도 지금보다 단순했습니다. VS / PS 고정 분리 비효율이 확실한 손해로 체감되는 구간이 지금보다 덜했습니다. 그러다보니 "일을 동적으로 나눠주는 로직(스케줄러, 디스패처, 레지스터 파일, 컨텍스트 스위칭 등)" 을 넣는 비용은 당시 공정, 전력, 검증 대비 이득이 불확실했죠.
하지만 DX10 / SM4에서는 셰이더 길이와 픽셀 작업 비중이 커지면서 로드 불균형이 더 자주 체감되기 시작했습니다. 동시에 기술의 발전으로 비용도 낮아지면서 스테이지별 제약을 정리(거의 동일한 명령어, 레지스터, 리소스 접근)하고 통합된 셰이더 모델을 전제로 설계를 재정의하면서 Unified Shader 구조가 자리잡게 됩니다.
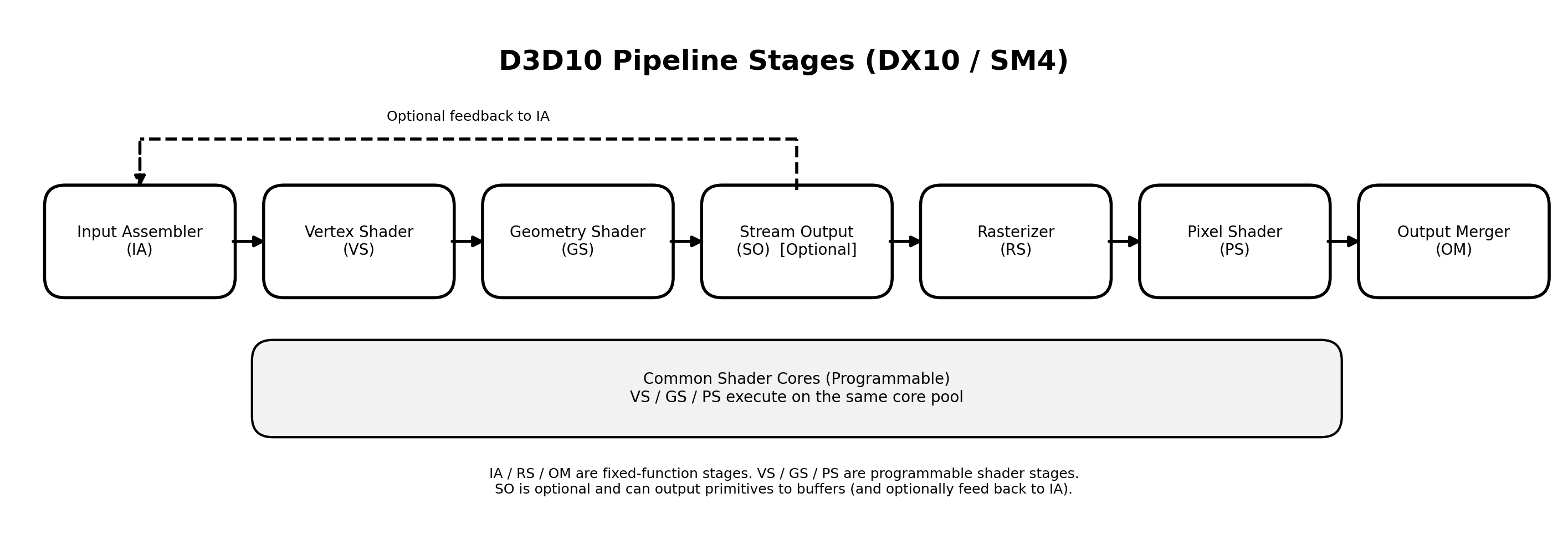
Direct3D 10 그래픽 파이프라인의 공식 단계 순서를 그대로 배치하고 그 위에 Unified Shader(= Common Shader Cores)이 무엇을 뜻하는지 함께 표시한 그림입니다. 핵심은 두 층으로 나뉩니다.
- 위쪽 : DX10의 파이프라인 단계(stage)
- 아래쪽 : VS/GS/PS가 실행되는 공용 연산 자원(core pool)
즉, 단계(stage)가 통합된 것이 아니라 Programmable 단계가 같은 연산 자원을 공유하게 된 것이 Unified shader의 포인트 입니다.
단계별 의미
1) Input Assembler (IA)
- 버텍스 버퍼/인덱스 버퍼에서 데이터를 읽어와서
- “정점 스트림”을 조립해 다음 단계로 넘긴다.
2) Vertex Shader (VS) (Programmable)
- 정점 단위 연산을 수행한다.
(좌표 변환, 스키닝, 정점 속성 계산 등)
3) Geometry Shader (GS) (Programmable)
- 프리미티브(삼각형/라인/포인트) 단위로 연산한다.
- 필요하면 프리미티브를 증감/변형할 수 있다.
4) Stream Output (SO) [Optional]
- GS의 결과(또는 파이프라인 중간 결과)를 버퍼로 기록하는 옵션 단계다.
- 그림의 **점선 화살표(Feedback)**는 SO에 저장한 데이터를 다시 IA로 재투입할 수 있음을 나타낸다.
(즉 “GPU 안에서 결과를 저장→다시 입력으로 사용”하는 루프가 가능)
5) Rasterizer (RS)
- 정점/프리미티브를 **픽셀 후보(프래그먼트)**로 변환한다.
- 화면 공간으로 투영하고, 클리핑/컬링 같은 고정 기능 처리도 포함된다.
6) Pixel Shader (PS) (Programmable)
- 픽셀(프래그먼트) 단위 연산을 수행한다.
- 텍스처 샘플링, 조명 계산, 머티리얼 평가 같은 대부분의 “화면 품질” 연산이 여기서 발생한다.
7) Output Merger (OM)
- PS의 출력 색/깊이 결과를 최종 렌더 타깃에 합성한다.
- 블렌딩, 깊이/스텐실 테스트 같은 “최종 합성 규칙”이 적용된다.
Common Shader Cores가 의미하는 것
DX10 / SM4에서 VS, GS, PS는 같은 종류의 Programmable Core에서 실행될 수 있습니다. 따라서 어떤 프레임에서 픽셀 작업이 많으면 PS쪽에 코어가 더 배정되고, 정점 / 지오메트리 작업이 많으면 VS / GS 쪽에 코어가 더 배정되는 식입니다. 따라서 로드 불균형을 줄이는 방향으로 하드웨어가 설계된 것입니다.
중요한 점
- 파이프라인 "단계"는 여전히 존재합니다.(IA > VS > GS > SO (Optional) > RS > PS > OM 순서 유지)
- Unified Shader는 단계 통합이 아니라 연산 자원 통합(공용 코어 풀)입니다.
맺음말
정리하면 DX10/SM4의 Unified Shader는 파이프라인 단계가 사라진 것이 아니라, VS / GS / PS가 같은 실행 자원(공용 코어 풀)을 공유하도록 바뀐 구조 변화입니다. 그 결과 프레임마다 달라지는 워크로드에 맞춰 연산 자원을 더 유연하게 배분할 수 있게 되었고, DX9 시절의 로드 불균형 문제도 완화되는 방향으로 설계가 이동했습니다. 다음 글에서는 이 통합 구조 위에서 SM5 시대로 넘어가며 무엇이 확장됐는지 이어서 보겠습니다.
다음글
UE4 전기: Unified Shader 이후
UE3 - Forward Rendering을 넘어 Deferred Rendering으로UE2의 Overlay Shader와 초기 Post Process EffectGPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금
chessire.tistory.com
GPU의 역사 - 4 : DX11(SM5), Tessellation과 Compute Shader
GPU의 역사 - 3 : DX10/SM4와 Unified Shader 전환GPU의 역사 - 2 : SIMD에서 SIMT로, Branch DivergenceGPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금
chessire.tistory.com
이전글
GPU의 역사 - 2 : SIMD에서 SIMT로, Branch Divergence
GPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금처럼 복잡한 셰이더 기반 렌더링이 불가능했습니다. VRAM 용량도 32~64MB 수준이라 SSAA
chessire.tistory.com
UE3 - Forward Rendering을 넘어 Deferred Rendering으로
UE2의 Overlay Shader와 초기 Post Process EffectGPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금처럼 복잡한 셰이더 기반 렌더링이 불가능했
chessire.tistory.com
'Game Programming > Graphics' 카테고리의 다른 글
| GPU의 역사 - 5 : DX12(SM6), Wave Intrinsics로 드러난 하드웨어 아키텍처 (0) | 2026.02.10 |
|---|---|
| GPU의 역사 - 4 : DX11(SM5), Tessellation과 Compute Shader (0) | 2026.01.28 |
| GPU의 역사 - 2 : SIMD에서 SIMT로, Branch Divergence (0) | 2025.12.05 |
| GPU의 역사 - 1 : FFP에서 SIMD까지 (0) | 2025.11.28 |
| 레이트레이싱(ray tracing) 기법 (0) | 2021.04.15 |