
CPU는 SIMD를 ‘더 강한 벡터’로 키웠고,
GPU는 SIMD를 ‘스레드 추상화’로 바꿨다.
지난 시간 FFP에서 고전 SIMD의 등장까지 알아보았습니다. 이제 SIMD에서 SIMT로 넘어가던 DirectX9 ~ DirectX10 시절을 알아보도록 하겠습니다.
개요
하나의 명령어로 여러 데이터를 동시에 처리하던 고전 SIMD는 구조적인 한계가 명확했습니다.
- 데이터 길이가 workload에 맞지 않으면 cost 낭비가 발생
- 스레드 개념이 없음
- 분기 시 lane이 갈라지면 실행이 직렬화되어 효율(활성 lane 비율)이 크게 하락
- gather/scatter 미지원 => 다양한 메모리 주소 접근이 불가능
이 구조는 단순한 벡터 연산에는 강력하지만,
픽셀·조명·텍스처·조건문이 많은 실제 그래픽스 workload에는 치명적이었다.
CPU는 SIMD 폭을 확장하고 ISA를 강화하는 방식으로 발전 방향을 잡았습니다.
- 벡터 폭 증가
- gather/scatter 지원 (일반 load/store 관점)
- mask 연산 강화
- 분기 최소화 등
즉, CPU는 SIMD를 더 강한 벡터 처리 장치로 발전시키는 방향을 택했다.
SIMT의 등장
하지만 GPU는 완전히 다른길을 선택했습니다. 그것은 바로 SIMD를 Thread로 추상화하여 재해석하는 방법입니다. GPU는 수천 ~ 수만 개의 Pixel Fragment를 병렬 처리해야 했기 때문에 PC(ProgramCounter)를 Thread마다 하나씩 둘 수 없었습니다. PC를 Thread마다 하나씩 두면 면적과 전력소모가 폭발적으로 증가하기 때문이었습니다.
그래서 GPU는 SIMD를 다음과 같이 재해석했습니다.
"SIMD lane을 Thread처럼 보이게 만들고,
프로그래머에게는 각 lane이 독립적인 스레드처럼 보이게 하자."
이 방식이 바로 SIMT 모델입니다.
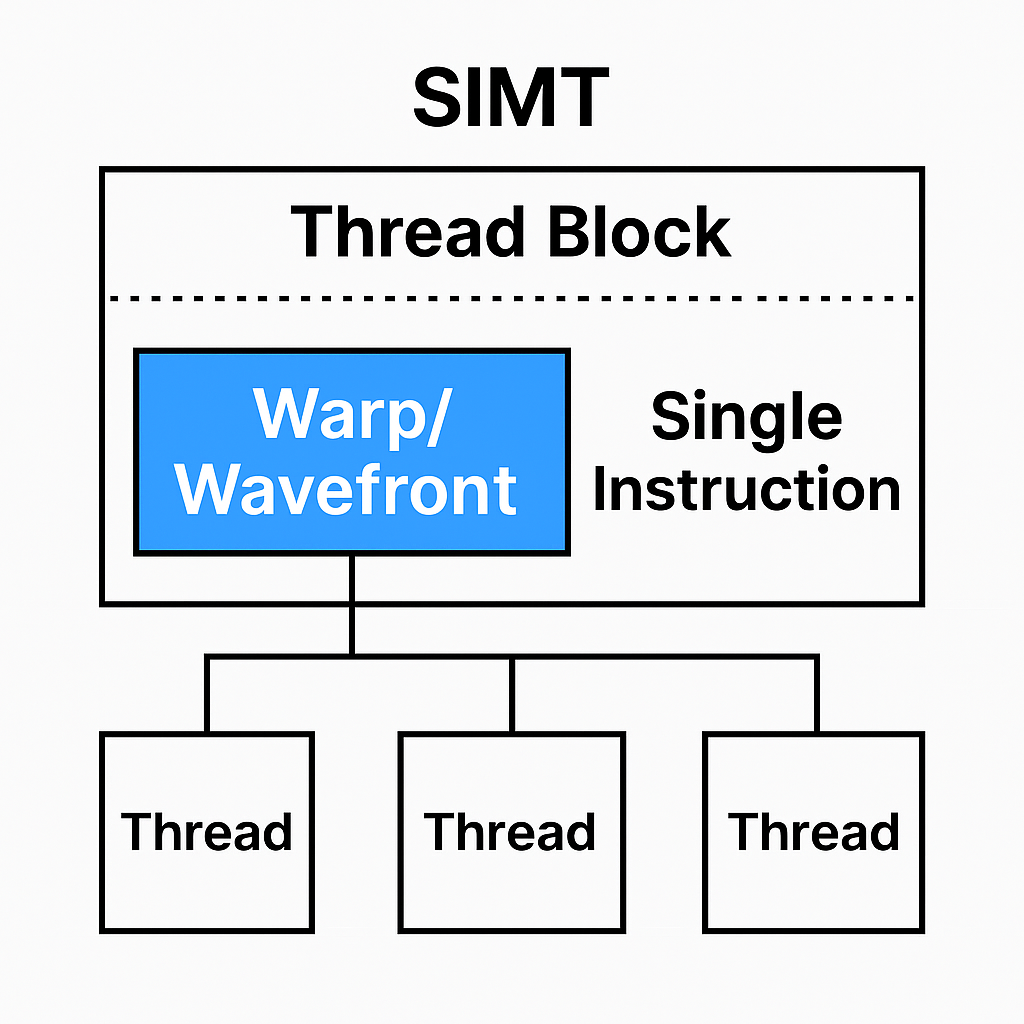
Warp란 무엇인가?
CPU는 Thread마다 PC가 하나씩 있습니다. 그렇기 때문에 완전한 MIMD 실행 모델로 각자 다른 위치에서 다른 코드를 실행할 수 있습니다. 하지만 GPU의 Warp의 구조는 정반대입니다.
예를 들어 Warp = 32 thread가 있다면,
(벤더/세대에 따라 warp/wavefront 크기가 다를 수 있음)
32개의 스레드는 각자 독립적으로 보이지만,
Warp 전체가 PC 1개,
그렇기 때문에 32개의 스레드는 한번에 동일한 명령어만 실행 가능.
각 Thread는 고유한 Register 값을 갖지만 명령어 흐름은 공유.
이렇게 동일한 명령어를 동시에 실행하는 한 단계가 Lockstep입니다.
Branch Divergence
이 조건을 보면 Lockstep의 의미가 바로 드러납니다.
아래와 같은 조건이 나왔다고 합시다.
if (x < 16)
A 실행
else if(x < 32)
B 실행
- thread 0 ~ 15 => A 실행
- thread 16 ~ 31 => B 실행
이렇게 CPU 에서는 스레드 별로 명령어를 다르게 실행할 수 있기 때문에 각 스레드에서 A와 B를 나눠서 실행하게 됩니다. 하지만 GPU는 Warp는 하나의 PC만 있으므로 두 경로를 동시에 실행할 수 없습니다.
그렇기에 SIMT는 다음과 같은 방식으로 처리합니다.
Thread 32개를 컨트롤 하는 Warp의 PC를
- A 경로로 이동
- true thread만 활성 (mask = on)
- false thread는 비활성 (mask = off)
- Warp 실행(A만 실행 됨)
- B 경로로 이동
- false thread만 활성 (mask = on)
- true thread는 비활성 (mask = off)
- Warp 실행 (B만 실행 됨)
이렇게 한 warp 안에서 분기가 갈리면, warp는 A와 B를 직렬화해 순차적으로 실행합니다. 이것이 lockstep 실행의 제약인 Branch Divergence입니다. 고전 SIMD에서도 분기 직렬화는 실행 효율을 떨어뜨렸습니다. 다만 SIMT에서는 warp 단위로 작업이 쪼개져 있고, 실행 유닛이 다른 warp를 교대로 실행하며 파이프라인을 유지하기 때문에, “전체가 멈춘다”기보다는 활성 lane 감소로 효율이 하락하는 형태로 나타납니다.
맺음말
SIMT의 등장은 고전 SIMD의 한계를 '극복'했다기보다는, 그래픽스라는 특수한 workload를 처리하기 위한 현실적인 타협이었습니다.
- SIMD lane을 Thread처럼 추상화하여 프로그래머에게는 MIMD처럼 보이게 만들고
- 내부에서는 여전히 lockstep 기반 SIMD의 효율을 유지하며
- Massive Parallel Pixel Workload를 감당할 수 있도록 한 구조
즉, SIMT는 "GPU스럽게 동작하는 MIMD의 환상"을 만들어낸 모델이라고 할 수 있습니다.
Branch divergence는 여전히 존재하며 성능을 떨어뜨립니다. 하지만 FFP 시대에는 상상할 수 없었던 복잡한 조명, 그림자, 포스트 프로세싱, 물리 기반 셰이딩을 GPU가 처리할 수 있게 된 것도 결국 이 SIMT 모델 덕분입니다.
다음 글에서는 이 SIMT 모델이 어떻게 구체적으로 구현되었는지, 그리고 DirectX10~11, UE3~UE4 시대를 지나면서 하드웨어와 셰이더 모델이 어떤 방향으로 진화했는지를 이어서 다뤄보겠습니다.
다음글
GPU의 역사 - 3 : DX10/SM4와 Unified Shader 전환
GPU의 역사 - 2 : SIMD에서 SIMT로, Branch DivergenceGPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금처럼 복잡한 셰이더 기반 렌더링이 불가
chessire.tistory.com
이전글
GPU의 역사 - 1 : FFP에서 SIMD까지
그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금처럼 복잡한 셰이더 기반 렌더링이 불가능했습니다. VRAM 용량도 32~64MB 수준이라 SSAA나 고급 조명 기법을 적용하기
chessire.tistory.com
UE2의 Overlay Shader와 초기 Post Process Effect
GPU의 역사 - 1 : FFP에서 SIMD까지그래픽카드의 한계 2000년대 초반의 GPU는 FFP(Fixed Function Pipeline)중심이었고, 지금처럼 복잡한 셰이더 기반 렌더링이 불가능했습니다. VRAM 용량도 32~64MB 수준이라 SSAA
chessire.tistory.com
'Game Programming > Graphics' 카테고리의 다른 글
| GPU의 역사 - 4 : DX11(SM5), Tessellation과 Compute Shader (0) | 2026.01.28 |
|---|---|
| GPU의 역사 - 3 : DX10/SM4와 Unified Shader 전환 (0) | 2026.01.09 |
| GPU의 역사 - 1 : FFP에서 SIMD까지 (0) | 2025.11.28 |
| 레이트레이싱(ray tracing) 기법 (0) | 2021.04.15 |
| Direct3D9 랜더링파이프라인 (0) | 2010.02.26 |